




 Selasa, Maret 31, 2015
Selasa, Maret 31, 2015
 coretan asti
coretan asti
DOWNLOAD FILE

TUGAS
04
MAKALAH
ORGANISASI
BERKAS
INDEXED
SEQUENTIAL
Disusun
Oleh:
Nama : ASTI WIDYANINGSIH
NIM :
121051032
JURUSAN
TEKNIK INFORMATIKA
FAKULTAS
TEKNOLOGI INDUSTRI
INSTITUT
SAINS & TEKNOLOGI AKPRIND
YOGYAKARTA
2015
KATA PENGANTAR
A. Organisasi Berkas Indexed Sequential




B.
Struktur Pohon dan Pohon Biner
Dalam Organisasi Berkas Indexed Sequential




C. Virtual Storage Access Method (VSAM)
D. Indexed Sequential Access Method (ISAM)
E.
Implementasi Indexed Sequential


DAFTAR PUSTAKA
KATA PENGANTAR
Alhamdulillahirobbil‘alamin,
puji
dan syukur kami panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan
hidayah-Nya, sehingga kami dapat menyelesaikan tulisan ini mengenai “Organisasi Berkas Indexed Sequential”.
Tulisan ini disusun guna memenuhi syarat ketuntasan kegiatan belajar mengajar
mata kuliah Sistem Berkas Institut Sains & Teknologi AKPRIND Yogyakarta
sekaligus untuk mengembangkan pengetahuan kami.
Kami
ucapkan terima kasih kepada berbagai pihak yang telah membantu dan mendukung
penyelesaian tulisan ini, antara lain :
1.
Bapak Edhy Sutanta, S.T., M.Kom., selaku
dosen mata kuliah Sistem Bekas.
2.
Orang tua yang telah memberikan dukungan
baik secara material maupun imaterial.
3.
Berbagai pihak yang telah membantu.
Kami menyadari bahwa
kemampuan dalam menulis masih banyak kekurangan. Untuk itu kami mohon maaf dan
dengan kerendahan hati, kami bersedia menerima kritik saran yang bersifat
membangun untuk memperbaiki tulisan ini.
Yogyakarta,
30 Maret 2015
Asti
Widyaningsih
LEMBAR
JUDUL
KATA
PENGANTAR
DAFTAR ISI
PENDAHULUAN
A. Latar
Belakang Masalah
B. Batasan
Masalah
C. Rumusan
Masalah
D. Tujuan
E. Manfaat
PEMBAHASAN
A. Organisasi
Berkas Indexed Sequential
B. Struktur
Pohon dan Pohon Biner Dalam Organisasi Berkas Indexed Sequential
C. Virtual Storage Access Method (VSAM)
D. Indexed Sequential Access Method (ISAM)
E. Implementasi
Indexed Sequential
F. Keuntungan Dan Kerugian Pada
Organisasi Berkas Indexed Sequential
PENUTUP
A. Simpulan
B. Saran
DAFTAR PUSTAKA
BAB I
Sistem adalah suatu
kumpulan atau himpunan dari unsur atau variabel-variabel yang saling
terorganisasi, saling berinteraksi dan saling bergantung satu sama lain (Fatta,
2007). Setiap sistem memiliki tujuan dan tujuan inilah yang menjadi motivasi
yang mengarahkan sistem. Tanpa tujuan, sistem menjadi tidak terkendali. Tentu
tujuan antara satu sistem dengan sistem yang lain berbeda (jagatsisteminformasi.blogspot.com,
30 Maret 2015).
Berkas adalah kumpulan
informasi berkait yang diberi nama dan direkam pada tempat penyimpanan
sekunder. Dari sudut pandang pengguna, berkas merupakan bagian terkecil dari
penyimpanan logis, artinya data tidak akan dapat ditulis ke penyimpanan sekunder
kecuali jika berada dalam berkas. Biasanya berkas merepresentasikan program
(baik source maupun bentuk objek) dan
data. Data dari berkas dapat bersifat numeric, alfabetik, alfanumerik, ataupun
biner. Format berkas juga bebas, misalnya berkas teks. Secara umum, berkas
adalah urutan bit, byte, baris atau catatan yang didefinisikan oleh pembuat
berkas atau pengguna. Informasi dalam berkas ditentukan oleh pembuatnya. Ada
banyak ragam jenis informasi yang dapat disimpan dalma berkas, sesuai dengan
jenisnya masing-masing. Contohnya text
file: urutan karakter yang disusun ke dalam baris-baris (Pangera dan
Ariyus, 2005).
Sistem Berkas adalah
sistem penyimpanan pengorganisasian, pengelolaan data pada alat penyimpanan
eksternal, dengan menggunakan teknik organisasi data tertentu. Organisasi
berkas adalah teknik atau cara untuk menyatakan dan menyimpan record-record
dalam berkas/file. Record adalah merupakan kumpulan dari data yang terstruktur.
Dalam record setiap elemen bisa mempunyai data yang berbeda antara satu dengan
yang lainnya (raodhotulm.blogspot.com, 29 Maret 2015). Model dasar organisasi
berkas/file terdiri atas 3 macam, yaitu: Sequential
File, Random File, dan Indexed Sequential
File (Noersasongko dan Andoko, 2010). Pada makalah ini akan dibahas
mengenai organisasi berkas indexed sequential.
Pada pembahasan makalah ini meliputi pengertian dari organisasi berkas indexed
sequential, struktur pohon dan pohon biner
dalam organisasi berkas indexed
sequential, pengertian Virtual Storage Access Method (VSAM), pengertian Indexed Sequential Access Method
(ISAM), implementasi indexed sequential, serta keuntungan dan
kerugian pada organisasi berkas index
sequential.
Berdasarkan latar belakang dan batasan masalah di atas, maka rumusan
masalah dalam makalah ini yaitu:
1.
Apa yang dimaksud dengan organisasi berkas indexed
sequential?
2.
Apa itu struktur pohon dan pohon biner dalam organisasi berkas indexed
sequential?
3.
Apa yang dimaksud dengan Virtual
Storage Access Method (VSAM)?
4.
Apa yang dimaksud dengan Indexed
Sequential Access Method (ISAM)?
5.
Apa saja implementasi indexed
sequential?
6.
Apa keuntungan dan kerugian pada organisasi berkas index sequential?
Penulisan
makalah ini bertujuan untuk mengetahui pengertian dari organisasi berkas indexed
sequential, struktur pohon dan pohon biner
dalam organisasi berkas indexed
sequential, pengertian Virtual Storage Access Method (VSAM), pengertian Indexed Sequential Access Method
(ISAM), implementasi indexed sequential, serta keuntungan dan
kerugian pada organisasi berkas index
sequential.
Manfaat yang diharapkan dari
penulisan makalah ini agar pembaca dapat memperoleh pengetahuan mengenai pengertian
dari organisasi berkas indexed sequential, struktur
pohon dan pohon biner dalam organisasi berkas indexed sequential, pengertian Virtual
Storage Access Method (VSAM), pengertian Indexed Sequential Access Method (ISAM), implementasi indexed sequential, serta keuntungan dan kerugian pada organisasi
berkas index sequential.
BAB II
A. Organisasi Berkas Indexed Sequential
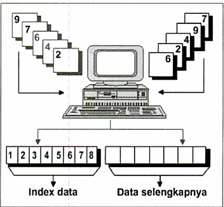
Noersasongko
dan Andoko (2010) mengatakan bahwa index sequential file merupakan perpaduan terbaik dari teknik sequential dan random file. Teknik penyimpanan yang dilakukan menggunakan suatu
indeks yang isinya berupa bagian dari data yang sudah disortir. Indeks ini
diakhiri dengan adanya pointer (penunjuk) yang bisa menunjukkan secara jelas
posisi data yang selengkapnya. Indeks yang ada juga merupakan record key (kunci record), sehingga
kalau record key ini dipanggil, seluruh data juga akan ikut terpanggil.
Gambar 1. Index
Sequential File, perpaduan antara
Sequential
File dan Random
File.
Kita bisa melihat daftar isi pada sebuah buku untuk
membayangkan penyimpanan data menggunakan teknik index sequential. Pada bagian di sebelah kiri disebut sebagai
indeks data yang berisi bagian dari data yang ada. Indeks data kemudian
diakhiri dengan pointer yang menunjukkan posisi keseluruhan isi data.
Gambar 2. Daftar isi pada buku merupakan analogi index sequential.
Uraian berikut mengilustrasikan teknik dalam metode index sequential file. Terdapat sebuah
data nilai mahasiswa yang terdiri Nomor, Nama, Nilai 1, Nilai 2, dan Nilai 3.
Gambar 3. Data awal.
Data tersebut bisa disimpan menggunakan Nomor sebagai indeks.
Dengan demikian, apabila data tersebut dicetak akan dihasilkan suatu data yang
berurutan berdasarkan Nomor. Nomor yang ada akan tersusun dengan urutan dari
kecil ke urutan yang lebih besar.
Gambar 4. Data yang menggunakan Nomor sebagai indeks.
Pada contoh
berikut, Nama juga bisa dijadikan sebagai index. Apabila data tersebut dicetak,
akan dihasilkan suatu data yang berurutan berdasarkan Nama. Nama yang ada akan
tersusun dengan urutan dari kecil ke urutan yang paling besar.
Gambar 5. Data yang menggunakan Nama sebagai indeks.
Organisasi berkas index sequential adalah berkas/file yang disusun sedemikian rupa
sehingga dapat diakses secara sequential (berurutan) maupun secara direct (langsung) atau kombinasi
keduanya. Atau bisa diartikan bahwa berkas index
sequential ini merupakan kombinasi dari berkas sequential dan berkas
relatif. Organisasi berkas ini mirip dengan organisasi berkas sequential dimana setiap rekaman disusun
secara beruntun di dalam file, hanya saja ada tambahan indeks yang digunakan
untuk mencatat posisi atau alamat dari suatu kunci rekaman di dalam file (raodhotulm.blogspot.com,
29 Maret 2015).
Jenis Acces yang di perbolehkan dalam Berkas Indeks
Sequential yaitu (anidotnet.blogspot.com/, 30 Maret 2015):
1.
Akses Sekuensial
2.
Akses Direct
Sedangkan jenis prosesnya yaitu:
1.
Batch
2.
Interactive
Struktur Berkas Indeks sekuensial yaitu:
1.
Indeks
2.
Binary Search Tree
3.
Data
4.
Sekuensial
B.
Struktur Pohon dan Pohon Biner
Dalam Organisasi Berkas Indexed Sequential
Dalam dpratiwi.staff.gunadarma.ac.id
(2015) dipaparkan bahwa sebuah pohon (tree)
adalah struktur dari sekumpulan elemen, dengan salah satu elemennya merupakan
akarnya atau root, dan sisanya yang
lain merupakan bagian-bagian pohon yang terorganisasi dalam susunan berhirarki,
dengan root sebagai puncaknya. Contoh
umum dimana struktur pohon sering ditemukan adalah pada penyusunan silsilah
keluarga, hirarki suatu organisasi, daftar isi suatu buku dan lain sebagainya.
Contoh:
Gambar
6. Silsilah Keluarga.
Akar pohon (root) adalah Handoko. Secara rekursif suatu struktur pohon dapat
didefinisikan sebagai berikut:
1.
Sebuah simpul tunggal adalah sebuah
pohon.
2.
Bila terdapat simpul n, dan beberapa
sub-pohon T1,T2,...,Tk, yang tidak saling berhubungan, yang masing-masing
akarnya adalah n1,n2,...,nk , dari simpul/sub pohon ini dapat dibuat sebuah
pohon baru dengan n sebagai akar dari simpul-simpul n1,n2,...,nk.
Gambar 7. Definisi struktur pohon.
Salah satu tipe pohon
yang paling banyak dipelajari adalah pohon biner. Pohon Biner adalah pohon yang
setiap simpulnya memiliki paling banyak dua buah cabang/anak.
Gambar 8. Beberapa contoh pohon
biner.
Gambar 9.Contoh pohon biner.
Gambar 10. Pohon biner yang
direpresentasikan dalam tabel.
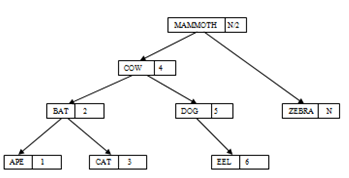
Pada gambar tersebut
memperlihatkan struktur berkas indeks sekuensial dengan sebuah indeks berikut
pointer yang menuju ke berkas data sekuensial. Pada contoh gambar tersebut,
indeksnya disusun berdasarkan binary search tree. Indeksnya digunakan untuk
melayani sebuah permintaan untuk mengakses sebuah record tertentu, sedangkan
berkas data sekeunsial digunakan untuk mendukung akses sekuensial terhadap
seluruh kumpulan record-record.
C. Virtual Storage Access Method (VSAM)
VSAM (Virtual Access Storage Method) adalah metode
akses untuk sistem IBM kerangka utama operasi, MVS, sekarang disebut z/OS. VSAM
berhasil dan diperluas metode akses file IBM sebelumnya, ISAM (Indexed Sequential Access Method).
Menggunakan VSAM, suatu perusahaan dapat mengatur catatan dalam file dalam
urutan fisik (urutan bahwa mereka masuk), urutan logis menggunakan kunci
(misalnya, nomor ID karyawan), atau dengan jumlah record relatif pada perangkat
penyimpanan akses langsung (DASD).
Ada empat jenis data set VSAM:
1.
Entry Sequenced Data Set
(ESDS)
2.
Key Sequenced Data Set
(KSDS)
3.
Linear Data Set (LDS)
4.
Relative Record Data Set
(RRDS)
Catatan VSAM
bisa panjang tetap atau variabel. Banyak perusahaan menjalankan kedua aplikasi
lama dan baru pada mainframe yang mengakses file VSAM (disebut juga data set). IBM
DB2 sekarang mempromosikan, sistem manajemen database relasional, meskipun
dataset linear VSAM masih digunakan mengandung tablespace dan indexspaces
dalam sistem. Mengetik urutan VSAM juga digunakan oleh DB2 untuk Boot Strap Dataset (BSD) (http://searchdatacenter.techtarget.com/definition/VSAM,
30 Maret 2015).
D. Indexed Sequential Access Method (ISAM)
ISAM (Indexed Sequential Access Method) adalah
sistem manajemen file yang dikembangkan di IBM yang memungkinkan catatan untuk
diakses baik secara berurutan (dalam urutan mereka dimasukkan) atau secara acak
(dengan indeks). Setiap indeks mendefinisikan urutan yang berbeda dari catatan.
Database karyawan dapat memiliki beberapa indeks, berdasarkan informasi yang
sedang dicari. Sebagai contoh, indeks nama dapat memerintahkan karyawan
berdasar abjad lalu, sementara indeks departemen dapat memerintahkan karyawan
dengan departemen mereka. Kunci ditentukan dalam setiap indeks. Untuk indeks
abjad nama karyawan, kolom nama terakhir akan menjadi kunci. ISAM dikembangkan
sebelum VSAM (Virtual Storage Access
Method) dan database relasional (http://searchdatacenter.techtarget.com/definition/ISAM,
30 Maret 2015).
E.
Implementasi Indexed Sequential
Ada 2 pendekatan dasar untuk mengimplementasikan
konsep dari organisasi berkas indeks sequential, yaitu (http://elearning.gunadarma.ac.id/,
29 Maret 2015):
1. Blok
Indeks dan Data (Dinamik)
2. Prime dan Overflow Data Area (Statik)
Kedua pendekatan tersebut mengunakan sebuah
bagian indeks dan sebuah bagian data, dimana masing-masing menempati berkas
yang terpisah. Karena Kedua pendekatan tersebut menggunakan bagian indeks
dan bagian data, dimana masing-masing menempati file yang terpisah. Karena
diimplementasikan pada organisasi internal yang berbeda. Masing-masing file
tersebut harus menempati pada alat penyimpan yang bersifat Direct Access Storage Device (DASD).
1. Blok
Indeks dan Data (Dinamik)
Pada pendekatan ini berkas indeks dan berkas
data diorganisasikan dalam blok. Berkas indeks mempunyai struktur tree, sedangkan berkas data mempunyai
struktur sekuensial dengan ruang bebas yang didistribusikan antar populasi
record.
Untuk cara pertama, kita menyusun data dengan
lebih memperhatikan ke data yang bersifat logik, bukan fisik. Jadi, data dan
index diorganisasikan ke dalam blok-blok. Blok-blok index diorganisasi secara
sequential (consecutive) dan
bertingkat-tingkat (misal setiap blok hanya berisi 4 record index yang berisi key field dan pointer).
Setiap tingkat akan menuju ke blok data (misal
setiap blok hanya berisi 4 record data) di tingkat selanjutnya dan
seterusnya menuju ke blok data yg akan mendapatkan record yg dicari secara direct. Bila dilakukan penyisipan data
dan blok tertentu (tempat data baru itu) sudah penuh (tidak ada tempat kosong/
padding lagi), maka akan dilakukan reorganisasi blok dengan membentuk blok
baru. Tentu, mungkin saja perubahan ini akan berdampak pada isi blok index-nya.
Bila dilakukan penyisipan data dan track
tertentu (tempat data baru itu) sudah penuh (tidak ada tempat kosong/padding
lagi), maka akan dilakukan reorganisasi track
dengan membentuk track baru. Tentu, track baru itu di luar prime data
file-nya, yaitu di overflow data
area-nya. Contohnya pada gambar di bawah ini.
Gambar 11. Contoh blok indeks & data (dinamic)
Pada gambar tersebut ada N blok data dan 3
tingkat dari indeks. Setiap entry pada indeks mempunyai bentuk (nilai key
terendah, pointer), dimana pointer menunjuk pada blok yang lain, dengan nilai
key-nya sebagai nilai key terendah. Setiap tingkat dari blok indeks menunjuk
seluruh blok, kecuali blok indeks pada tingkat terendah yang menunjuk ke blok
data.
Jika sebuah permintaan untuk mengakses record
tertentu, misal kita ingin mengakses dengan nilai key BAT, indeks dengan
tingkat tertinggi (dalam hal ini blok indeks 3-1) yang pertama yang akan dicari
pada contoh ini, pointer dari AARDVARK menunjuk blok indeks 2-1. Pointer yang
ditunjuk pada kotak tersebut adalah pointer yang berisikan AARDVARK, yang akan
menunjuk ke blok indeks 1-1. Pointer berikutnya yang akan ditunjuk adalah
pointer yang berisi BABOON, yang selanjutnya akan menunjuk blok data 2. Blok
data ini akan mencari untuk record dengan key tujuan, yaitu BAT, dimana pada
blok ini record tersebut ditemukan.
2. Prime dan Overflow Data Area (Statik)
Pendekatan lain untuk mengimplementasikan berkas
indeks sequential adalah berdasarkan struktur indeks dimana struktur indeks ini
lebih ditekankan pada karakteristik hardware (fisik) dari penyimpanan,
dibandingkan dengan distribusi secara logik dari nilai key. Indeksnya ada
beberapa tingkat, misalnya tingkat cylinder
index dan tingkat track index.
Berkas datanya secara umum diimplementasikan sebagai 2 berkas, yaitu prime area dan overflow area. Contohnya pada gambar di bawah ini.
Gambar 12. Contoh prime & overflow
data area (static).
Setiap cylinder
dari alat penyimpanan mempunyai 4 track. Pada berkas binatang ada 6 cylinder yang dialokasikan pada prime
data area. Track pertama (nomor 0) dari setiap cylinder berisi sebuah indeks pada record key dalam cylinder
tersebut. Dalam sebuah track data, tracknya disimpan secara urut berdasarkan
nilai key. Tingkat pertama dari indeks dalam berkas indeks dinamakan master
indeks. Tingkat kedua dari indeks dinamakan cylinder indeks. Entry pada master indeks: nilai key
tertinggi, pointer. Entry pada cylinder indeks: nilai key tertinggi,
nomor cylinder.
Contoh pengaksesan, misal: mengakses dengan nilai key BAT
1.
Pertama : Cari pada master indeks,
2.
Kedua : Karena BAT ada di depan LYNX, maka pointer dari LYNX akan
menunjuk ke cylinder index,
3.
Ketiga : Karena BAT ada di depan ELEPHANT, maka pointer dari
ELEPHANT akan menunjuk ke track 0 dari cylinder 1,
4.
Keempat : Karena BAT ada di belakang BABOON dan di depan COW, maka
pointer dari BABOON akan menunjuk ke track 2,
5.
Kelima : Cari secara sequential sampai BAT ditemukan.
Hal ini bisa disimpulkan: Permintaan
untuk mengakses data secara sequential akan dilakukan dengan
mengakses cylinder dan track dari berkas data prime secara urut.
F.
Keuntungan Dan Kerugian Pada Organisasi
Berkas Index Sequential
Dalam organisasi
berkas index sequential terdapat
keuntungan dan kerugian, yaitu (raodhotulm.blogspot.com,
29 Maret 2015):
1.
Kegunaan Sekaligus Keunggulan Index Sequential File
1.1 Bentuk file yang paling
banyak dipakai.
1.2 Dipakai bila file ingin
selalu dalam kondisi up to date.
1.3 Sebuah record dapat di
insert (dimasukkan/ditambah) atau di retrieve
(dibetulkan/dikembalikan semula) secara langsung melalui indexnya.
1.4 Sangat sesuai untuk
proses secara on-line.
1.5 Bisa juga diakses secara
sequential.
1.6 Mempunyai semua
keunggulan dari sequential file
2.
Kelemahan Index Sequential File
2.1 Search/pencarian hanya bisa melalui sebuah key saja, yaitu key yang
mengurutkan file Performance.
2.2 Diperlukan perubahan
data, maka seluruh record yang tersimpan didalam master file ini, harus
semuanya diproses terlebih dahulu.
2.3 Data yang tersimpan
harus sudah urut (sorted).
2.4 Posisi data yang
tersimpan sangat sulit untuk up-to-date,
sebab master file hanya bisa berubah saat proses selesai dilakukan.
2.5 Tidak bisa dilakukan
secara langsung.
BAB III
Berdasarkan
hasil pembahasan dapat disimpulkan bahwa:
1.
Organisasi berkas index sequential adalah berkas/file yang
disusun sedemikian rupa sehingga dapat diakses secara sequential (berurutan)
maupun secara direct (langsung) atau
kombinasi keduanya.
2.
Sebuah pohon (tree) adalah struktur dari sekumpulan elemen, dengan salah satu
elemennya merupakan akarnya atau root,
dan sisanya yang lain merupakan bagian-bagian pohon yang terorganisasi dalam
susunan berhirarki, dengan root
sebagai puncaknya.
3.
Pohon Biner adalah pohon yang setiap
simpulnya memiliki paling banyak dua buah cabang/anak.
4.
VSAM (Virtual Access Storage Method) adalah metode akses untuk sistem IBM kerangka utama
operasi, MVS, sekarang disebut z/OS.
5.
ISAM (Indexed Sequential Access Method) adalah
sistem manajemen file yang dikembangkan di IBM yang memungkinkan catatan untuk
diakses baik secara berurutan (dalam urutan mereka dimasukkan) atau secara acak
(dengan indeks).
6.
Ada 2 pendekatan dasar untuk mengimplementasikan konsep dari organisasi
berkas indeks sequential, yaitu Blok Indeks dan Data (Dinamik) dan Prime dan Overflow Data Area (Statik).
7.
Organisasi berkas index sequential memiliki keuntungan dan kerugian.
Kajian dalam makalah ini masih banyak
kekurangan, untuk itu kajian lebih lanjut mengenai organisasi berkas indexed sequential sangat diperlukan.
DAFTAR PUSTAKA
Fatta, H., A., 2007, Analisis & Perancangan Sistem Informasi, Yogyakarta: ANDI.
Noersasongko, E., dan Andoko, P., N., 2010, Mengenal Dunia Komputer, Jakarta: PT
Elex Media.
Pangera, A., A., dan Ariyus, D., 2005, Sistem Operasi, Yogyakarta: ANDI.
http://anidotnet.blogspot.com/2009/11/organisasi-berkas-indeks-sequential_01.html, diakses 30 Maret 2015.
http://anidotnet.blogspot.com/2009/11/organisasi-berkas-indeks-sequential_01.html, diakses 30 Maret 2015.
http://dpratiwi.staff.gunadarma.ac.id/Downloads/files/23468/bab5+Organisasi+Berkas+Index+Index+Sequential.DOC,
diakses 30 Maret 2015.
http://elearning.gunadarma.ac.id/docmodul/pengantar_berkas_&_akses/bab4_organisasi_berkas_index_sequential.pdf,
diakses 29 Maret 2015.
http://jagatsisteminformasi.blogspot.com/2013/05/pengertian-dan-definisi-sistem.html,
diakses 30 Maret 2015.
http://raodhotulm.blogspot.com/2014/05/organisasi-berkas-indeks-sequential.html,
diakses 29 Maret 2015.
http://searchdatacenter.techtarget.com/definition/ISAM,
diakses 30 Maret 2015
http://searchdatacenter.techtarget.com/definition/VSAM,
diakses 30 Maret 2015.




